I am primarily interested in demystifying language model internals (MechInterp) and operationalizing them (ActionableInterp) to build more responsible, controllable, trustworthy, and efficient NLP systems. If you’re interested in or actively working on model interpretability especially if you are from an underrepresented group, I’d love to chat and perhaps collaborate and/or mentor, please reach out!
Longer Bio
The past two summers, I interned at the semantic machines team at Microsoft Research and the cloud AI research team at Google working on actionable interpretability. Before CMU, I spent nearly two and a half years as a predoctoral researcher on the AllenNLP team at AI2, where I worked with Matt Peters. Before that I spent two years in industry at startups as a research scientist working on NLP, vision, speech, and multimodal applications. I have had the opportunity to work closely with some amazing collaborators at other institutions including Aaron Mueller, Jason Eisner, Ben Van Durme, Margaret Mitchell, Sasha Luccioni, Vladlen Koltun, and Doug Downey.
At ICML in Seoul to present ACUTE on using model internals for better confidence estimation for LLMs in both the main conference and at the MechInterp workshop!
As language models improve and become increasingly deployed to solve a variety of tasks, trustworthiness becomes essential. Calibration is a good proxy for trust: well-calibrated confidence estimates help inform the risk versus reward tradeoff when trusting a specific model output. Unfortunately, even as models improve, they remain poorly calibrated, often biasing towards overconfidence. Additionally, calibration can be gamed: a policy that always predicts the base rate is perfectly calibrated, but completely uninformative. To resolve this, we develop a new metric, expected utility renormalized by the oracle (EURO), that balances calibration and informativeness. We also propose a general-purpose activation-based confidence, utility, and trust estimation protocol (ACUTE) to appropriately adjudicate uncertainty. The ACUTE protocol provides flexible, sample-efficient, and compute-efficient confidence estimators for 3 tasks including multiple choice question answering, tool-calling, and scientific document summarization across 6 models from 4 model families. ACUTE outperforms strong baselines on EURO, while maintaining low calibration error. Taken together, our work shows that equipping LLMs with the ACUTE protocol can improve calibration, utility, and trustworthiness in numerous settings.
@article{subramani-etal-2026-acute,title={The ACUTE Protocol: Operationalizing Language Model Activations for Better Calibration, Utility,
and Trust},author={Subramani, Nishant and Goyal, Palash and Song, Yiwen and Malek, Mani and Xue, Yuan and Pfister, Tomas and Palangi, Hamid},journal={ICML},year={2026},url={https://arxiv.org/abs/2606.07822},paper_link={https://arxiv.org/abs/2606.07822},workshop={ICML (MechInterp)},workshop_two={ACL (TrustNLP)}}
ACL (BigPicture)
Harnessing the Latent Space: From Steering Vectors to Model Calibrators for Control and Trust
Language models have changed from unreliable text generators to highly-capable large models with trillions of parameters. Capability increases come hand-in-hand with increases in scale, making understanding the internal representations of models more challenging. Since millions of users increasing rely on language models to interact with external tools or make decisions in medium or high-stakes scenarios, we need to establish control over model behavior and know when to trust model outputs. In this paper, we discuss our contributions on harnessing the latent spaces by proposing steering vectors for control and developing latent space-based model calibrators for trust. Together, our contributions help demystify the latent spaces of language models and offer new insights into how to harness model internals to build more trustworthy language technology.
@article{subramani-2026-harnessing,title={Harnessing the Latent Space: From Steering Vectors to Model Calibrators for Control and Trust},author={Subramani, Nishant},journal={BigPicture Workshop at ACL},year={2026},url={https://aclanthology.org/2026.bigpicture-main.10/},paper_link={https://aclanthology.org/2026.bigpicture-main.10/},}
COLM (SciFM)
How Much Do Circuits Tell Us? Measuring the Consistency and Specificity of Language Model Circuits
The circuits framework in mechanistic interpretability aims to identify causally important sparse subgraphs of model components, typically evaluated by measuring necessity and sufficiency. We measure circuit reuse, the proportion of components shared across per-example circuits within a task, and investigate two less-studied properties of this: consistency, the recurrence of components within a task, and specificity, their uniqueness to a task. Using edge attribution patching across six tasks and seven models, we find that within-task reuse is high and that shared components are necessary for task performance, with ablations causing up to ∼100% relative accuracy drops. However, circuits turn out not to be task-specific: ablating one task’s circuit damages another task’s performance about as much as that task’s own circuit does. We discover that this is due to substantial overlap between circuits across tasks, which are causally important for performance. Some circuits do contain a smaller set of task-specific components, but these account for only a modest portion of circuit performance. Overall, our findings suggest that while circuit discovery at the level of attention heads and MLP layers identifies important components, their lack of task-specificity raises questions about the degree to which circuits can support targeted understanding and intervention on model behavior.
@article{li-subramani-2026-circuits-consistency-specificity,title={How Much Do Circuits Tell Us? Measuring the Consistency and Specificity of Language Model Circuits},author={Li, Michael and Subramani, Nishant},journal={COLM (SciFM)},year={2026},url={https://arxiv.org/abs/2605.08348},paper_link={https://arxiv.org/abs/2605.08348},}
ACL
Model Internal Sleuthing: Finding Lexical Identity and Inflectional Features in Modern Language Models
Large transformer-based language models dominate modern NLP, yet our understanding of how they encode linguistic information relies primarily on studies of early models like BERT and GPT-2. Building on classic BERTology work, we analyze 25 models spanning from classical architectures (BERT, DeBERTa, GPT-2) to modern large language models (Pythia, OLMo-2, Gemma-2, Qwen2.5, Llama-3.1), probing layer-by-layer representations across eight linguistic tasks in English. Consistent with earlier findings, we find that hierarchical organization persists in modern models: early layers capture syntax, middle layers handle semantics and entity-level information, and later layers encode discourse phenomena. We dive deeper, conducting an in-depth multilingual analysis of two specific linguistic properties - lexical identity and inflectional morphology - that help disentangle form from meaning. We find that lexical information concentrates linearly in early layers but becomes increasingly nonlinear deeper in the network, while inflectional information remains linearly accessible throughout all layers. Additional analyses of attention mechanisms, steering vectors, and pretraining checkpoints reveal where this information resides within layers, how it can be functionally manipulated, and how representations evolve during pretraining. Taken together, our findings suggest that, even with substantial advances in LLM technologies, transformer models learn to organize linguistic information in similar ways, regardless of model architecture, size, or training regime, indicating that these properties are important for next token prediction. Our code is available at https://github.com/ml5885/model_internal_sleuthing.
@article{LiSubramani2026ModelInternalSleuthing,title={Model Internal Sleuthing: Finding Lexical Identity and Inflectional Features in Modern Language Models},author={Li, Michael and Subramani, Nishant},journal={ACL},year={2026},url={https://arxiv.org/abs/2506.02132},paper_link={https://arxiv.org/abs/2506.02132},}
Modern language models (LM) are trained on large scrapes of the Web, containing millions of personal information (PI) instances, many of which LMs memorize, increasing privacy risks. In this work, we develop the regexes and rules (R&R) detector suite to detect email addresses, phone numbers, and IP addresses, which outperforms the best regex-based PI detectors. On a manually curated set of 483 instances of PI, we measure memorization: finding that 13.6% are parroted verbatim by the Pythia-6.9b model, i.e., when the model is prompted with the tokens that precede the PI in the original document, greedy decoding generates the entire PI span exactly. We expand this analysis to study models of varying sizes (160M-6.9B) and timesteps of pretraining (70k-143k iterations) on the Pythia model suite and find that both model size and amount of pretraining are positively correlated with memorization. Even the smallest model, Pythia-160m, parrots 2.7% of the instances exactly. Consequently, we strongly recommend that pretraining datasets be aggressively filtered and anonymized to minimize PI parroting. The code for our detectors can be found at https://github.com/nishantsubramani/rr_pi_detectors/.
@article{subramani-etal-2026-personal,title={Personal Information Parroting in Language Models},author={Subramani, Nishant and Ghate, Kshitish and Diab, Mona},journal={Findings of EACL},year={2026},url={https://aclanthology.org/2026.findings-eacl.45.pdf},paper_link={https://aclanthology.org/2026.findings-eacl.45.pdf},workshop={ICML (MEMFM)},workshop_two={ACL (L2M2)}}
EMNLP ICML (R2FM)
SimBA: Simplifying Benchmark Analysis Using Performance Matrices Alone
Nishant Subramani*, Alfredo Gomez*, and Mona T. Diab
Modern language models are evaluated on large benchmarks, which are difficult to make sense of, especially for model selection. Looking at the raw evaluation numbers themselves using a model-centric lens, we propose SimBA, a three phase framework to Simplify Benchmark Analysis. The three phases of SimBA are: stalk, where we conduct dataset & model comparisons, prowl, where we discover a representative subset, and pounce, where we use the representative subset to predict performance on a held-out set of models. Applying SimBA to three popular LM benchmarks: HELM, MMLU, and BigBenchLite reveals that across all three benchmarks, datasets and models relate strongly to one another (stalk). We develop an representative set discovery algorithm which covers a benchmark using raw evaluation scores alone. Using our algorithm, we find that with 6.25% (1/16), 1.7% (1/58), and 28.4% (21/74) of the datasets for HELM, MMLU, and BigBenchLite respectively, we achieve coverage levels of at least 95% (prowl). Additionally, using just these representative subsets, we can both preserve model ranks and predict performance on a held-out set of models with near zero mean-squared error (pounce). Taken together, SimBA can help model developers improve efficiency during model training and dataset creators validate whether their newly created dataset differs from existing datasets in a benchmark. Our code is open source, available at https://github.com/nishantsubramani/simba.
@inproceedings{subramani-etal-2025-simba,title={Sim{BA}: Simplifying Benchmark Analysis Using Performance Matrices Alone},author={Subramani, Nishant and Gomez, Alfredo and Diab, Mona T.},booktitle={Findings of EMNLP},year={2025},url={https://www.arxiv.org/abs/2510.17998},paper_link={https://www.arxiv.org/abs/2510.17998},workshop={ICML (R2FM)},}
NAACL COLM (Interplay)
MICE for CATs: Model-Internal Confidence Estimation for Calibrating Agents with Tools
Nishant Subramani, Jason Eisner, Justin Svegliato, Benjamin Van Durme, Yu Su, and Sam Thomson
Tool-using agents that act in the world need to be both useful and safe. Well-calibrated model confidences can be used to weigh the risk versus reward of potential actions, but prior work shows that many models are poorly calibrated. Inspired by interpretability literature exploring the internals of models, we propose a novel class of model-internal confidence estimators (MICE) to better assess confidence when calling tools. MICE first decodes from each intermediate layer of the language model using logit lens (nostalgebraist, 2020) and then computes similarity scores between each layer’s generation and the final output. These features are fed into a learned probabilistic classifier to assess confidence in the decoded output. On the simulated trial and error (STE) tool-calling dataset using Llama3 models, we find that MICE beats or matches the baselines on smoothed expected calibration error. Using MICE confidences to determine whether to call a tool significantly improves over strong baselines on a new metric, expected tool-calling utility. Further experiments show that MICE is sample-efficient, can generalize zero-shot to unseen APIs, and results in higher tool-calling utility in scenarios with varying risk levels. Our code is open source, available at https://github.com/microsoft/mice_for_cats.
@inproceedings{subramani-etal-2025-mice,title={{MICE} for {CAT}s: Model-Internal Confidence Estimation for Calibrating Agents with Tools},author={Subramani, Nishant and Eisner, Jason and Svegliato, Justin and Van Durme, Benjamin and Su, Yu and Thomson, Sam},editor={Chiruzzo, Luis and Ritter, Alan and Wang, Lu},booktitle={Proceedings of NAACL},month=apr,year={2025},address={Albuquerque, New Mexico},publisher={Association for Computational Linguistics},url={https://aclanthology.org/2025.naacl-long.615/},pages={12362--12375},isbn={979-8-89176-189-6},workshop={COLM (Interplay)},paper_link={https://aclanthology.org/2025.naacl-long.615/},}
ACL 🏆 Best Paper
OLMo: Accelerating the Science of Language Models
Dirk Groeneveld, Iz Beltagy, Evan Walsh, Akshita Bhagia, Rodney Kinney, Oyvind Tafjord, Ananya Jha, Hamish Ivison, Ian Magnusson, Yizhong Wang, Shane Arora, David Atkinson, and 31 more authors
Language models (LMs) have become ubiquitous in both NLP research and in commercial product offerings. As their commercial importance has surged, the most powerful models have become closed off, gated behind proprietary interfaces, with important details of their training data, architectures, and development undisclosed. Given the importance of these details in scientifically studying these models, including their biases and potential risks, we believe it is essential for the research community to have access to powerful, truly open LMs. To this end, we have built OLMo, a competitive, truly Open Language Model, to enable the scientific study of language models. Unlike most prior efforts that have only released model weights and inference code, we release OLMo alongside open training data and training and evaluation code. We hope this release will empower the open research community and inspire a new wave of innovation.
@inproceedings{groeneveld-etal-2024-olmo,title={{OLM}o: Accelerating the Science of Language Models},author={Groeneveld, Dirk and Beltagy, Iz and Walsh, Evan and Bhagia, Akshita and Kinney, Rodney and Tafjord, Oyvind and Jha, Ananya and Ivison, Hamish and Magnusson, Ian and Wang, Yizhong and Arora, Shane and Atkinson, David and Authur, Russell and Chandu, Khyathi and Cohan, Arman and Dumas, Jennifer and Elazar, Yanai and Gu, Yuling and Hessel, Jack and Khot, Tushar and Merrill, William and Morrison, Jacob and Muennighoff, Niklas and Naik, Aakanksha and Nam, Crystal and Peters, Matthew and Pyatkin, Valentina and Ravichander, Abhilasha and Schwenk, Dustin and Shah, Saurabh and Smith, William and Strubell, Emma and Subramani, Nishant and Wortsman, Mitchell and Dasigi, Pradeep and Lambert, Nathan and Richardson, Kyle and Zettlemoyer, Luke and Dodge, Jesse and Lo, Kyle and Soldaini, Luca and Smith, Noah and Hajishirzi, Hannaneh},editor={Ku, Lun-Wei and Martins, Andre and Srikumar, Vivek},booktitle={Proceedings of ACL},month=aug,year={2024},address={Bangkok, Thailand},publisher={Association for Computational Linguistics},url={https://aclanthology.org/2024.acl-long.841},paper_link={https://arxiv.org/abs/2402.00838},}
ACL 🏆 Best Resource Paper
Dolma: an Open Corpus of Three Trillion Tokens for Language Model Pretraining Research
Luca Soldaini, Rodney Kinney, Akshita Bhagia, Dustin Schwenk, David Atkinson, Russell Authur, Ben Bogin, Khyathi Chandu, Jennifer Dumas, Yanai Elazar, Valentin Hofmann, Ananya Jha, and 24 more authors
Information about pretraining corpora used to train the current best-performing language models is seldom discussed: commercial models rarely detail their data, and even open models are often released without accompanying training data or recipes to reproduce them. As a result, it is challenging to conduct and advance scientific research on language modeling, such as understanding how training data impacts model capabilities and limitations. To facilitate scientific research on language model pretraining, we curate and release Dolma, a three-trillion-token English corpus, built from a diverse mixture of web content, scientific papers, code, public-domain books, social media, and encyclopedic materials. We extensively document Dolma, including its design principles, details about its construction, and a summary of its contents. We present analyses and experimental results on intermediate states of Dolma to share what we have learned about important data curation practices. Finally, we open-source our data curation toolkit to enable reproduction of our work as well as support further research in large-scale data curation.
@inproceedings{soldaini-etal-2024-dolma,title={Dolma: an Open Corpus of Three Trillion Tokens for Language Model Pretraining Research},author={Soldaini, Luca and Kinney, Rodney and Bhagia, Akshita and Schwenk, Dustin and Atkinson, David and Authur, Russell and Bogin, Ben and Chandu, Khyathi and Dumas, Jennifer and Elazar, Yanai and Hofmann, Valentin and Jha, Ananya and Kumar, Sachin and Lucy, Li and Lyu, Xinxi and Lambert, Nathan and Magnusson, Ian and Morrison, Jacob and Muennighoff, Niklas and Naik, Aakanksha and Nam, Crystal and Peters, Matthew and Ravichander, Abhilasha and Richardson, Kyle and Shen, Zejiang and Strubell, Emma and Subramani, Nishant and Tafjord, Oyvind and Walsh, Evan and Zettlemoyer, Luke and Smith, Noah and Hajishirzi, Hannaneh and Beltagy, Iz and Groeneveld, Dirk and Dodge, Jesse and Lo, Kyle},booktitle={Proceedings of ACL},year={2024},publisher={Association for Computational Linguistics},url={https://aclanthology.org/2024.acl-long.840},paper_link={https://arxiv.org/abs/2402.00159},}
ACL
Extracting Latent Steering Vectors from Pretrained Language Models
Nishant Subramani, Nivedita Suresh, and Matthew Peters
Prior work on controllable text generation has focused on learning how to control language models through trainable decoding, smart-prompt design, or fine-tuning based on a desired objective. We hypothesize that the information needed to steer the model to generate a target sentence is already encoded within the model. Accordingly, we explore a different approach altogether: extracting latent vectors directly from pretrained language model decoders without fine-tuning. Experiments show that there exist steering vectors, which, when added to the hidden states of the language model, generate a target sentence nearly perfectly (> 99 BLEU) for English sentences from a variety of domains. We show that vector arithmetic can be used for unsupervised sentiment transfer on the Yelp sentiment benchmark, with performance comparable to models tailored to this task. We find that distances between steering vectors reflect sentence similarity when evaluated on a textual similarity benchmark (STS-B), outperforming pooled hidden states of models. Finally, we present an analysis of the intrinsic properties of the steering vectors. Taken together, our results suggest that frozen LMs can be effectively controlled through their latent steering space.
@inproceedings{subramani-etal-2022-extracting,title={Extracting Latent Steering Vectors from Pretrained Language Models},author={Subramani, Nishant and Suresh, Nivedita and Peters, Matthew},editor={Muresan, Smaranda and Nakov, Preslav and Villavicencio, Aline},booktitle={Findings of ACL},month=may,year={2022},address={Dublin, Ireland},publisher={Association for Computational Linguistics},url={https://aclanthology.org/2022.findings-acl.48},paper_link={https://arxiv.org/abs/2205.05124/},}
BigScience Workshop
BLOOM: A 176B-Parameter Open-Access Multilingual Language Model
Teven Le Scao, Angela Fan, Christopher Akiki, Ellie Pavlick, Suzana Ili’c, Daniel Hesslow, Roman Castagn’e, Alexandra Sasha Luccioni, François Yvon, Matthias Gallé, Jonathan Tow, Alexander M. Rush, and 379 more authors
Large language models (LLMs) have been shown to be able to perform new tasks based on a few demonstrations or natural language instructions. While these capabilities have led to widespread adoption, most LLMs are developed by resource-rich organizations and are frequently kept from the public. As a step towards democratizing this powerful technology, we present BLOOM, a 176B-parameter open-access language model designed and built thanks to a collaboration of hundreds of researchers. BLOOM is a decoder-only Transformer language model that was trained on the ROOTS corpus, a dataset comprising hundreds of sources in 46 natural and 13 programming languages (59 in total). We find that BLOOM achieves competitive performance on a wide variety of benchmarks, with stronger results after undergoing multitask prompted finetuning. To facilitate future research and applications using LLMs, we publicly release our models and code under the Responsible AI License.
@article{Scao2022BLOOMA1,title={BLOOM: A 176B-Parameter Open-Access Multilingual Language Model},author={Scao, Teven Le and Fan, Angela and Akiki, Christopher and Pavlick, Ellie and Ili'c, Suzana and Hesslow, Daniel and Castagn'e, Roman and Luccioni, Alexandra Sasha and Yvon, François and Gall{\'e}, Matthias and Tow, Jonathan and Rush, Alexander M. and Biderman, Stella and Webson, Albert and Ammanamanchi, Pawan Sasanka and Wang, Thomas and Sagot, Beno{\i}t and Muennighoff, Niklas and del Moral, Albert Villanova and Ruwase, Olatunji and Bawden, Rachel and Bekman, Stas and McMillan-Major, Angelina and Beltagy, Iz and Nguyen, Huu and Saulnier, Lucile and Tan, Samson and Suarez, Pedro Ortiz and Sanh, Victor and Laurenccon, Hugo and Jernite, Yacine and Launay, Julien and Mitchell, Margaret and Raffel, Colin and Gokaslan, Aaron and Simhi, Adi and Etxabe, Aitor Soroa and Aji, Alham Fikri and Alfassy, Amit and Rogers, Anna and Nitzav, Ariel Kreisberg and Xu, Canwen and Mou, Chenghao and Emezue, Chris C. and Klamm, Christopher and Leong, Colin and van Strien, Daniel Alexander and Adelani, David Ifeoluwa and Radev, Dragomir R. and Ponferrada, Eduardo Gonz'alez and Levkovizh, Efrat and Kim, Ethan and Natan, Eyal and Toni, Francesco De and Dupont, G{\'e}rard and Kruszewski, Germ{\'a}n and Pistilli, Giada and ElSahar, Hady and Benyamina, Hamza and Tran, Hieu Trung and Yu, Ian and Abdulmumin, Idris and Johnson, Isaac and Gonzalez-Dios, Itziar and de la Rosa, Javier and Chim, Jenny and Dodge, Jesse and Zhu, Jian and Chang, Jonathan and Frohberg, Jorg and Tobing, Josephine and Bhattacharjee, Joydeep and Almubarak, Khalid and Chen, Kimbo and Lo, Kyle and von Werra, Leandro and Weber, Leon and Phan, Long and Allal, Loubna Ben and Tanguy, Ludovic and Dey, Manan and Mu{\~n}oz, Manuel Romero and Masoud, Maraim and Grandury, Mar'ia and vSavsko, Mario and Huang, Max and Coavoux, Maximin and Singh, Mayank and Jiang, Mike Tian-Jian and Vu, Minh Chien and Jauhar, Mohammad A. and Ghaleb, Mustafa and Subramani, Nishant and Kassner, Nora and Khamis, Nurulaqilla and Nguyen, Olivier and Espejel, Omar and de Gibert, Ona and Villegas, Paulo and Henderson, Peter and Colombo, Pierre and Amuok, Priscilla and Lhoest, Quentin and Harliman, Rheza and Bommasani, Rishi and L'opez, Roberto and Ribeiro, Rui and Osei, Salomey and Pyysalo, Sampo and Nagel, Sebastian and Bose, Shamik and Muhammad, Shamsuddeen Hassan and Sharma, Shanya and Longpre, S. and Nikpoor, Somaieh and Silberberg, S. and Pai, Suhas and Zink, Sydney and Torrent, Tiago Timponi and Schick, Timo and Thrush, Tristan and Danchev, Valentin and Nikoulina, Vassilina and Laippala, Veronika and Lepercq, Violette and Prabhu, Vrinda and Alyafeai, Zaid and Talat, Zeerak and Raja, Arun and Heinzerling, Benjamin and Si, Chenglei and Salesky, Elizabeth and Mielke, Sabrina J. and Lee, Wilson Y. and Sharma, Abheesht and Santilli, Andrea and Chaffin, Antoine and Stiegler, Arnaud and Datta, Debajyoti and Szczechla, Eliza and Chhablani, Gunjan and Wang, Han and Pandey, Harshit and Strobelt, Hendrik and Fries, Jason Alan and Rozen, Jos and Gao, Leo and Sutawika, Lintang and Bari, M Saiful and Al-Shaibani, Maged S. and Manica, Matteo and Nayak, Nihal V. and Teehan, Ryan and Albanie, Samuel and Shen, Sheng and Ben-David, Srulik and Bach, Stephen H. and Kim, Taewoon and Bers, Tali and F{\'e}vry, Thibault and Neeraj, Trishala and Thakker, Urmish and Raunak, Vikas and Tang, Xiang and Yong, Zheng-Xin and Sun, Zhiqing and Brody, Shaked and Uri, Y and Tojarieh, Hadar and Roberts, Adam and Chung, Hyung Won and Tae, Jaesung and Phang, Jason and Press, Ofir and Li, Conglong and Narayanan, Deepak and Bourfoune, Hatim and Casper, Jared and Rasley, Jeff and Ryabinin, Max and Mishra, Mayank and Zhang, Minjia and Shoeybi, Mohammad and Peyrounette, Myriam and Patry, Nicolas and Tazi, Nouamane and Sanseviero, Omar and von Platen, Patrick and Cornette, Pierre and Lavall'ee, Pierre Franccois and Lacroix, R{\'e}mi and Rajbhandari, Samyam and Gandhi, Sanchit and Smith, Shaden and Requena, St{\'e}phane and Patil, Suraj and Dettmers, Tim and Baruwa, Ahmed and Singh, Amanpreet and Cheveleva, Anastasia and Ligozat, Anne-Laure and Subramonian, Arjun and N'ev'eol, Aur'elie and Lovering, Charles and Garrette, Daniel H and Tunuguntla, Deepak R. and Reiter, Ehud and Taktasheva, Ekaterina and Voloshina, Ekaterina and Bogdanov, Eli and Winata, Genta Indra and Schoelkopf, Hailey and Kalo, Jan-Christoph and Novikova, Jekaterina and Forde, Jessica Zosa and Tang, Xiangru and Kasai, Jungo and Kawamura, Ken and Hazan, Liam and Carpuat, Marine and Clinciu, Miruna and Kim, Najoung and Cheng, Newton and Serikov, Oleg and Antverg, Omer and van der Wal, Oskar and Zhang, Rui and Zhang, Ruochen and Gehrmann, Sebastian and Mirkin, Shachar and Pais, S. Osher and Shavrina, Tatiana and Scialom, Thomas and Yun, Tian and Limisiewicz, Tomasz and Rieser, Verena and Protasov, Vitaly and Mikhailov, Vladislav and Pruksachatkun, Yada and Belinkov, Yonatan and Bamberger, Zachary and Kasner, Zdenvek and Kasner, Zdeněk and Pestana, Amanda and Feizpour, Amir and Khan, Ammar and Faranak, Amy and Santos, Ananda Santa Rosa and Hevia, Anthony and Unldreaj, Antigona and Aghagol, Arash and Abdollahi, Arezoo and Tammour, Aycha and HajiHosseini, Azadeh and Behroozi, Bahareh and Ajibade, Benjamin Ayoade and Saxena, Bharat Kumar and Ferrandis, Carlos Mu{\~n}oz and Contractor, Danish and Lansky, David M. and David, Davis and Kiela, Douwe and Nguyen, Duong Anh and Tan, Edward and Baylor, Emi and Ozoani, Ezinwanne and Mirza, Fatim Tahirah and Ononiwu, Frankline and Rezanejad, Habib and Jones, H.A. and Bhattacharya, Indrani and Solaiman, Irene and Sedenko, Irina and Nejadgholi, Isar and Passmore, Jan and Seltzer, Joshua and Sanz, Julio Bonis and Fort, Karen and Dutra, L{\'i}via and Samagaio, Mairon and Elbadri, Maraim and Mieskes, Margot and Gerchick, Marissa and Akinlolu, Martha and McKenna, Michael and Qiu, Mike and Ghauri, Muhammed and Burynok, Mykola and Abrar, Nafis and Rajani, Nazneen and Elkott, Nour and Fahmy, Nourhan and Samuel, Olanrewaju and An, Ran and Kromann, R. P. and Hao, Ryan and Alizadeh, Samira and Shubber, Sarmad and Wang, Silas L. and Roy, Sourav and Viguier, Sylvain and Le, Thanh-Cong and Oyebade, Tobi and Le, Trieu Nguyen Hai and Yang, Yoyo and Nguyen, Zach and Kashyap, Abhinav Ramesh and Palasciano, Alfredo and Callahan, Alison and Shukla, Anima and Miranda-Escalada, Antonio and Singh, Ayush Kumar and Beilharz, Benjamin and Wang, Bo and de Brito, Caio Matheus Fonseca and Zhou, Chenxi and Jain, Chirag and Xu, Chuxin and Fourrier, Cl{\'e}mentine and Perin'an, Daniel Le'on and Molano, Daniel and Yu, Dian and Manjavacas, Enrique and Barth, Fabio and Fuhrimann, Florian and Altay, Gabriel and Bayrak, Giyaseddin and Burns, Gully and Vrabec, Helena U. and Bello, Iman I.B. and Dash, Isha and Kang, Ji Soo and Giorgi, John and Golde, Jonas and Posada, Jose David and Sivaraman, Karthi and Bulchandani, Lokesh and Liu, Lu and Shinzato, Luisa and de Bykhovetz, Madeleine Hahn and Takeuchi, Maiko and P{\`a}mies, Marc and Castillo, Mar{\'i}a Andrea and Nezhurina, Marianna and Sanger, Mario and Samwald, Matthias and Cullan, Michael and Weinberg, Michael and Wolf, M and Mihaljcic, Mina and Liu, Minna and Freidank, Moritz and Kang, Myungsun and Seelam, Natasha and Dahlberg, Nathan and Broad, Nicholas Michio and Muellner, Nikolaus and Fung, Pascale and Haller, Patricia and Haller, Patrick and Eisenberg, Renata and Martin, Robert and Canalli, Rodrigo and Su, Rosaline and Su, Ruisi and Cahyawijaya, Samuel and Garda, Samuele and Deshmukh, Shlok S and Mishra, Shubhanshu and Kiblawi, Sid and Ott, Simon and Sang-aroonsiri, Sinee and Kumar, Srishti and Schweter, Stefan and Bharati, Sushil Pratap and Laud, Tanmay and Gigant, Th{\'e}o and Kainuma, Tomoya and Kusa, Wojciech and Labrak, Yanis and Bajaj, Yashasvi and Venkatraman, Y. and Xu, Yifan and Xu, Ying and Xu, Yu and Tan, Zhee Xao and Xie, Zhongli and Ye, Zifan and Bras, Mathilde and Belkada, Younes and Wolf, Thomas},journal={ArXiv},year={2022},volume={abs/2211.05100},url={https://api.semanticscholar.org/CorpusID:253420279},paper_link={https://arxiv.org/abs/2211.05100/},}
NeurIPS
Can unconditional language models recover arbitrary sentences?
Nishant Subramani, Samuel Bowman, and Kyunghyun Cho
Neural network-based generative language models like ELMo and BERT can work effectively as general purpose sentence encoders in text classification without further fine-tuning. Is it possible to adapt them in a similar way for use as general-purpose decoders? For this to be possible, it would need to be the case that for any target sentence of interest, there is some continuous representation that can be passed to the language model to cause it to reproduce that sentence. We set aside the difficult problem of designing an encoder that can produce such representations and, instead, ask directly whether such representations exist at all. To do this, we introduce a pair of effective, complementary methods for feeding representations into pretrained unconditional language models and a corresponding set of methods to map sentences into and out of this representation space, the reparametrized sentence space. We then investigate the conditions under which a language model can be made to generate a sentence through the identification of a point in such a space and find that it is possible to recover arbitrary sentences nearly perfectly with language models and representations of moderate size without modifying any model parameters.
@article{subramani2019can,title={Can unconditional language models recover arbitrary sentences?},author={Subramani, Nishant and Bowman, Samuel and Cho, Kyunghyun},journal={Advances in NeurIPS},volume={32},year={2019},url={https://proceedings.neurips.cc/paper_files/paper/2019/file/48c8c3963853fff20bd9e8bee9bd4c07-Paper.pdf},paper_link={https://arxiv.org/abs/1907.04944/},}
you can reach me at MyFirstName dot MyLastName 23 at gmail!

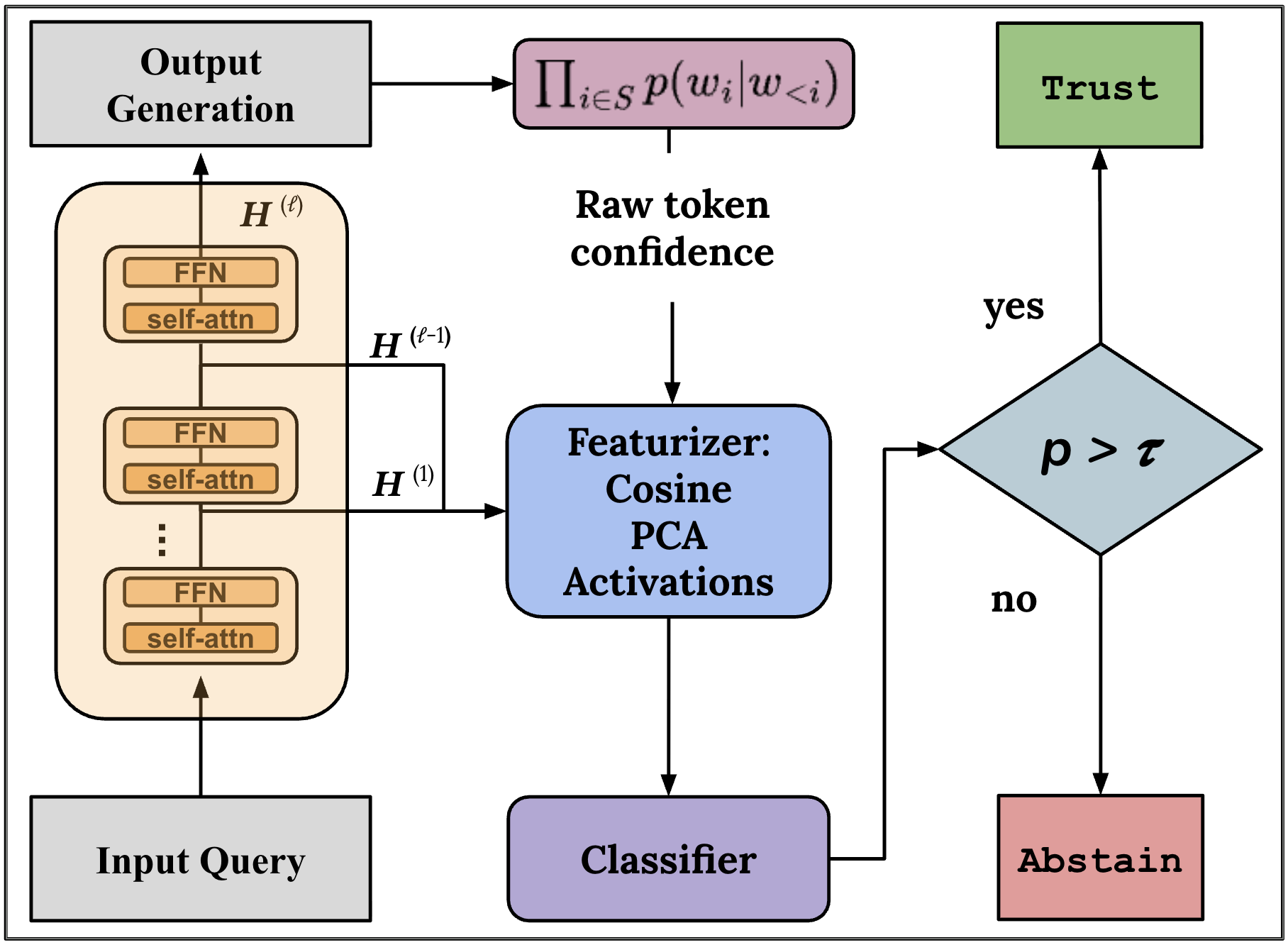 The ACUTE Protocol: Operationalizing Language Model Activations for Better Calibration, Utility, and TrustNishant Subramani, Palash Goyal, Yiwen Song, Mani Malek, Yuan Xue, Tomas Pfister, and Hamid PalangiICML, 2026
The ACUTE Protocol: Operationalizing Language Model Activations for Better Calibration, Utility, and TrustNishant Subramani, Palash Goyal, Yiwen Song, Mani Malek, Yuan Xue, Tomas Pfister, and Hamid PalangiICML, 2026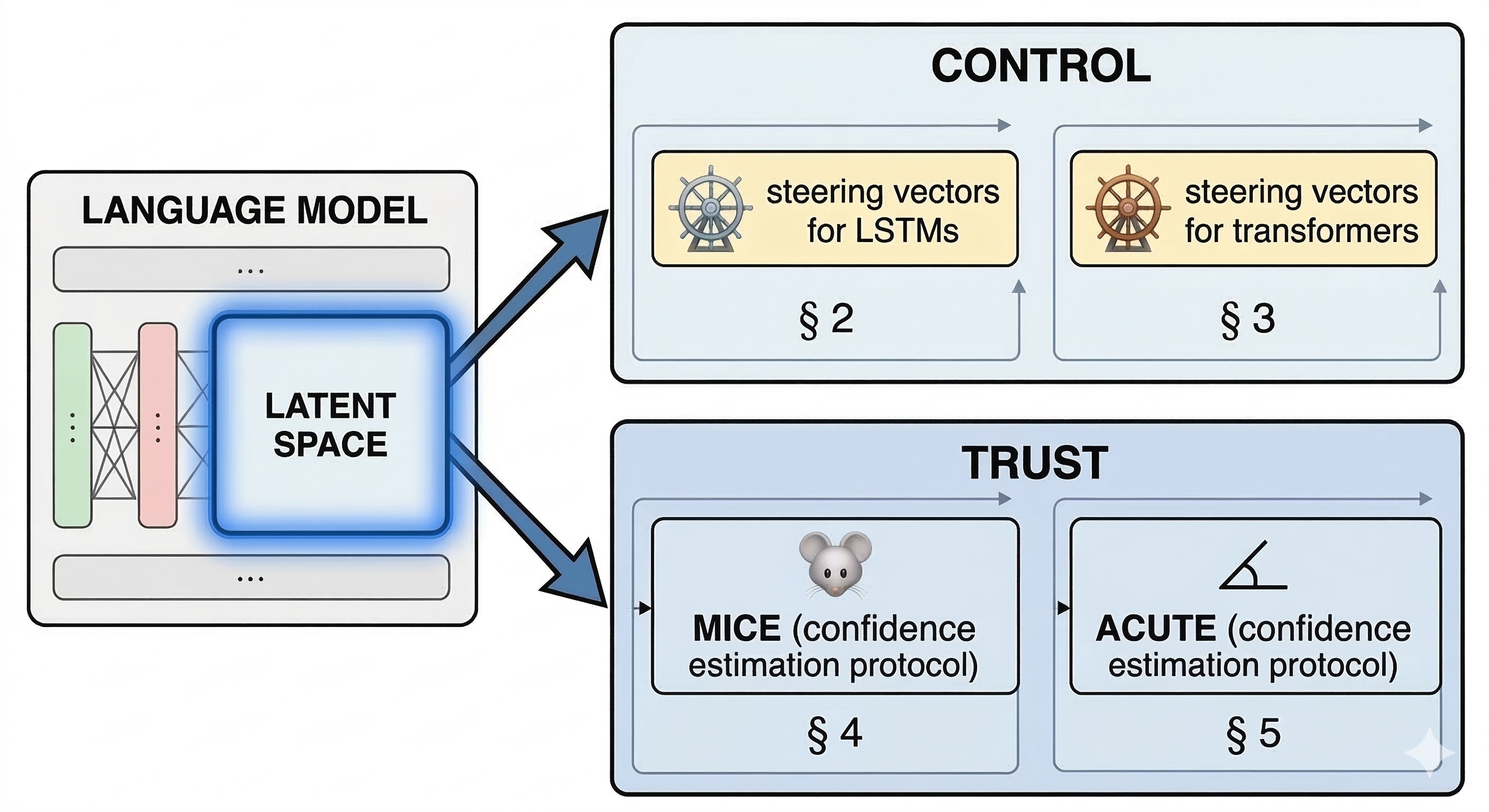 Harnessing the Latent Space: From Steering Vectors to Model Calibrators for Control and TrustNishant SubramaniBigPicture Workshop at ACL, 2026
Harnessing the Latent Space: From Steering Vectors to Model Calibrators for Control and TrustNishant SubramaniBigPicture Workshop at ACL, 2026 How Much Do Circuits Tell Us? Measuring the Consistency and Specificity of Language Model CircuitsMichael Li, and Nishant SubramaniCOLM (SciFM), 2026
How Much Do Circuits Tell Us? Measuring the Consistency and Specificity of Language Model CircuitsMichael Li, and Nishant SubramaniCOLM (SciFM), 2026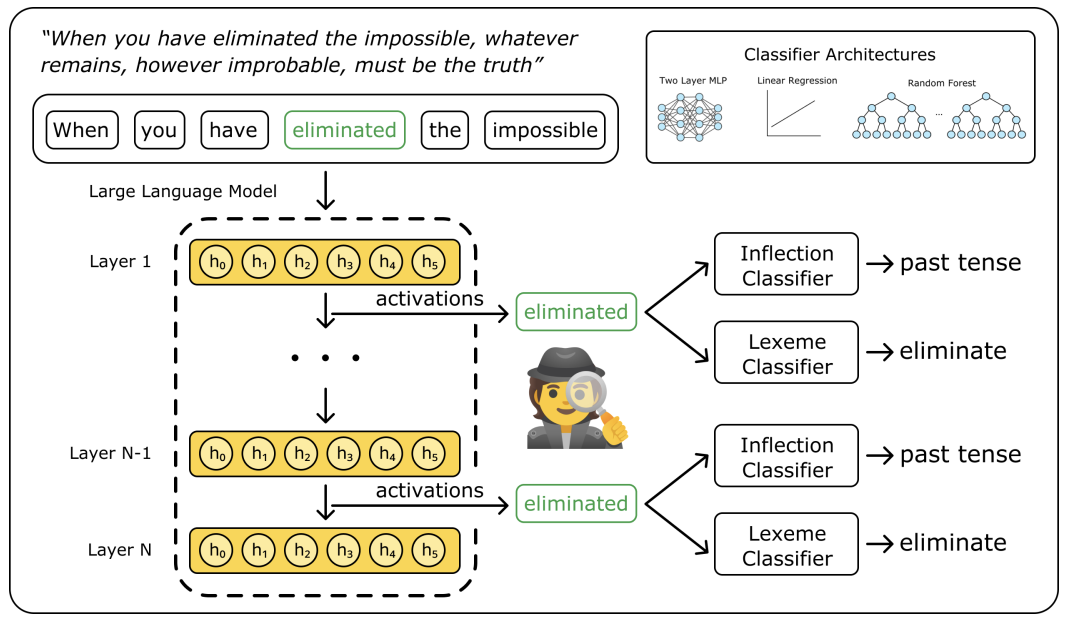 Model Internal Sleuthing: Finding Lexical Identity and Inflectional Features in Modern Language ModelsMichael Li, and Nishant SubramaniACL, 2026
Model Internal Sleuthing: Finding Lexical Identity and Inflectional Features in Modern Language ModelsMichael Li, and Nishant SubramaniACL, 2026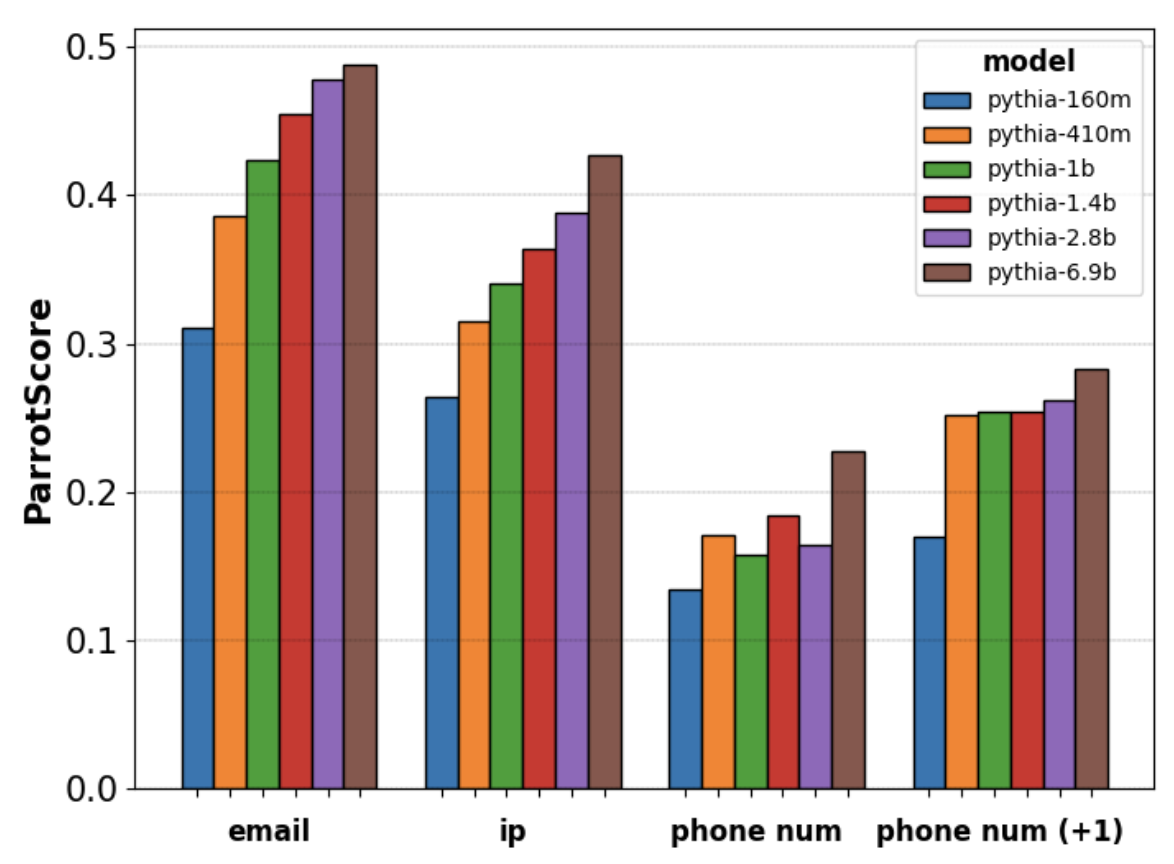 Personal Information Parroting in Language ModelsNishant Subramani, Kshitish Ghate, and Mona DiabFindings of EACL, 2026
Personal Information Parroting in Language ModelsNishant Subramani, Kshitish Ghate, and Mona DiabFindings of EACL, 2026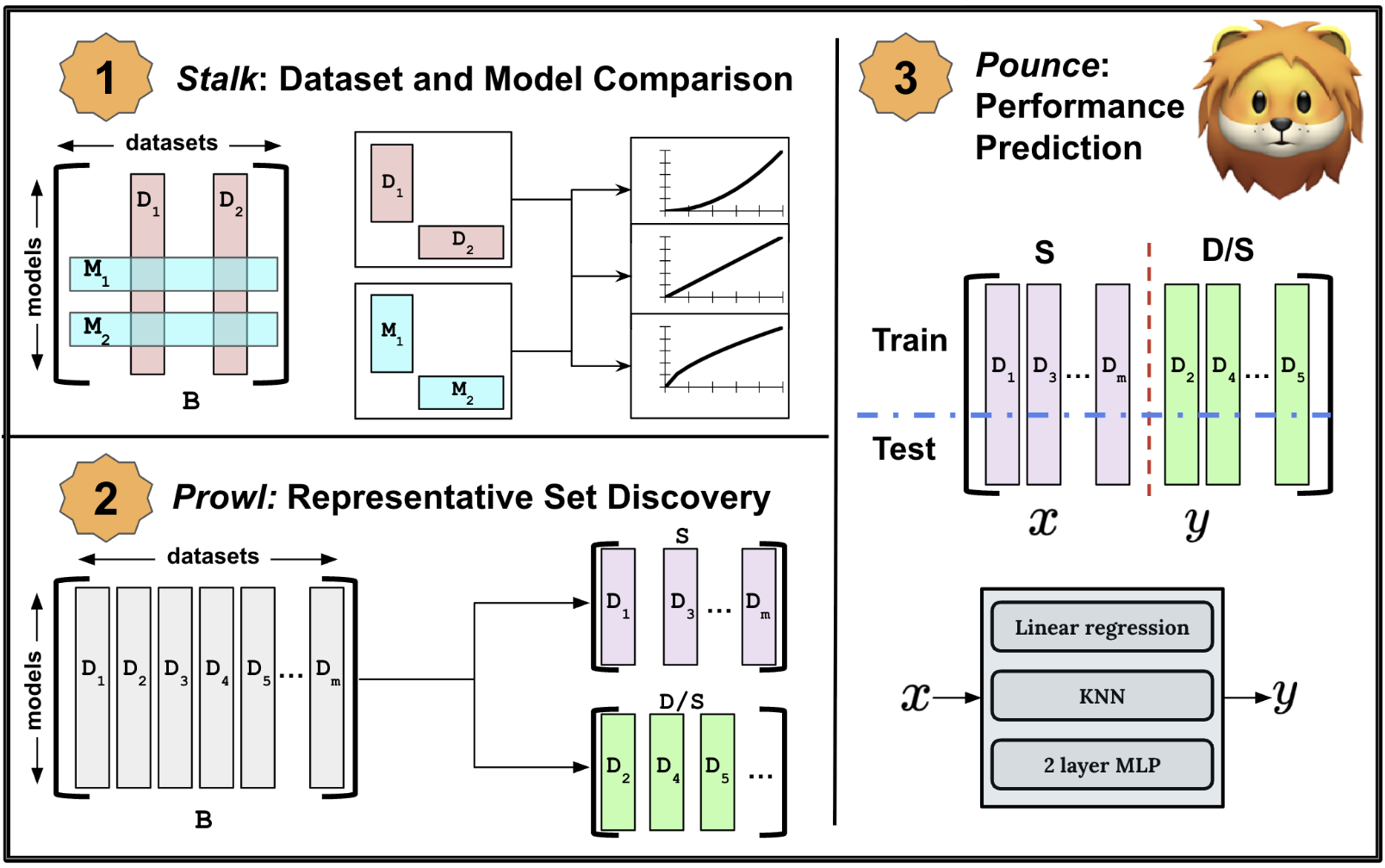 SimBA: Simplifying Benchmark Analysis Using Performance Matrices AloneNishant Subramani*, Alfredo Gomez*, and Mona T. DiabIn Findings of EMNLP, 2025
SimBA: Simplifying Benchmark Analysis Using Performance Matrices AloneNishant Subramani*, Alfredo Gomez*, and Mona T. DiabIn Findings of EMNLP, 2025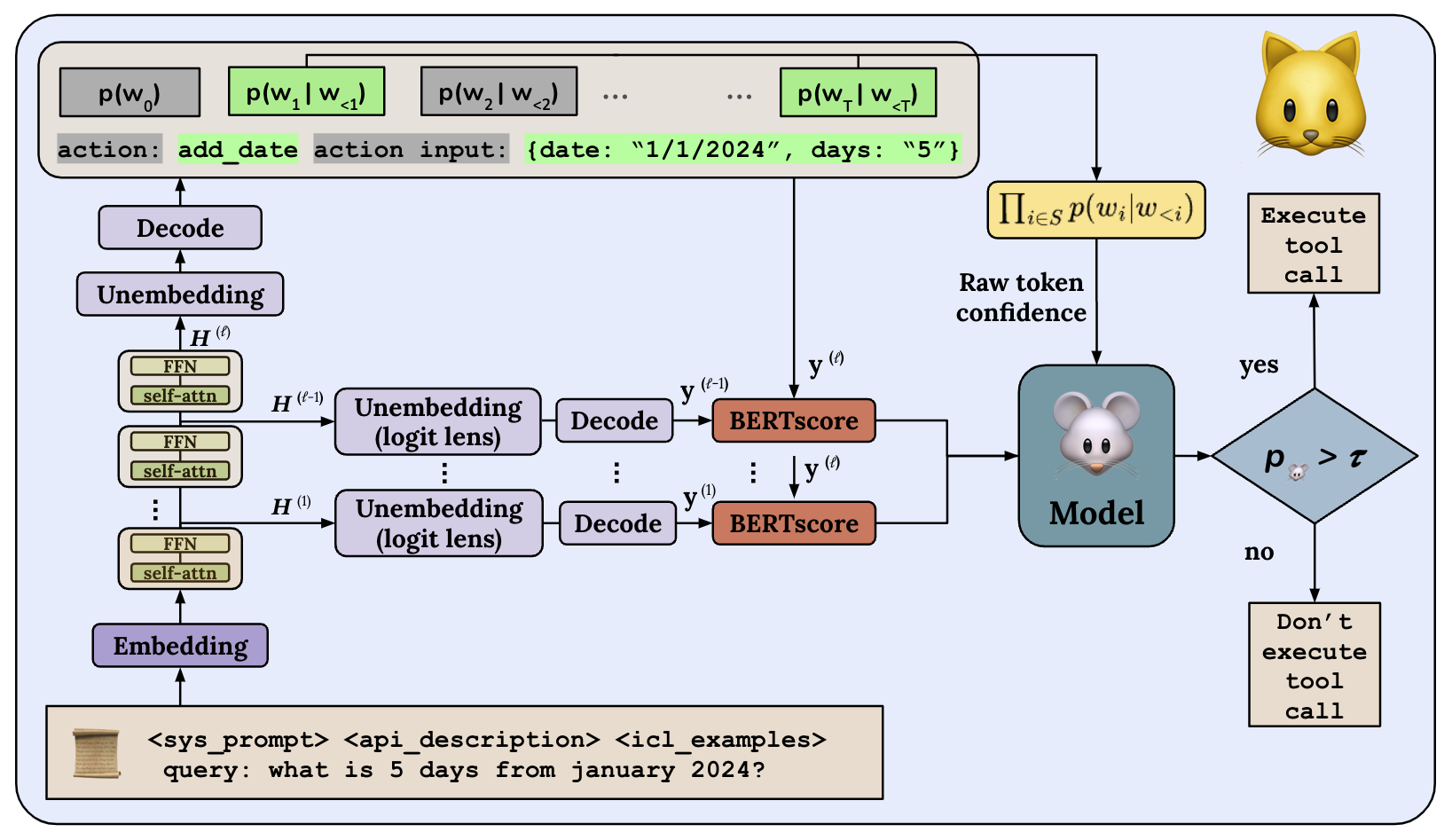 MICE for CATs: Model-Internal Confidence Estimation for Calibrating Agents with ToolsNishant Subramani, Jason Eisner, Justin Svegliato, Benjamin Van Durme, Yu Su, and Sam ThomsonIn Proceedings of NAACL, 2025
MICE for CATs: Model-Internal Confidence Estimation for Calibrating Agents with ToolsNishant Subramani, Jason Eisner, Justin Svegliato, Benjamin Van Durme, Yu Su, and Sam ThomsonIn Proceedings of NAACL, 2025 OLMo: Accelerating the Science of Language ModelsDirk Groeneveld, Iz Beltagy, Evan Walsh, Akshita Bhagia, Rodney Kinney, Oyvind Tafjord, Ananya Jha, Hamish Ivison, Ian Magnusson, Yizhong Wang, Shane Arora, David Atkinson, and 31 more authorsIn Proceedings of ACL, 2024
OLMo: Accelerating the Science of Language ModelsDirk Groeneveld, Iz Beltagy, Evan Walsh, Akshita Bhagia, Rodney Kinney, Oyvind Tafjord, Ananya Jha, Hamish Ivison, Ian Magnusson, Yizhong Wang, Shane Arora, David Atkinson, and 31 more authorsIn Proceedings of ACL, 2024 Dolma: an Open Corpus of Three Trillion Tokens for Language Model Pretraining ResearchLuca Soldaini, Rodney Kinney, Akshita Bhagia, Dustin Schwenk, David Atkinson, Russell Authur, Ben Bogin, Khyathi Chandu, Jennifer Dumas, Yanai Elazar, Valentin Hofmann, Ananya Jha, and 24 more authorsIn Proceedings of ACL, 2024
Dolma: an Open Corpus of Three Trillion Tokens for Language Model Pretraining ResearchLuca Soldaini, Rodney Kinney, Akshita Bhagia, Dustin Schwenk, David Atkinson, Russell Authur, Ben Bogin, Khyathi Chandu, Jennifer Dumas, Yanai Elazar, Valentin Hofmann, Ananya Jha, and 24 more authorsIn Proceedings of ACL, 2024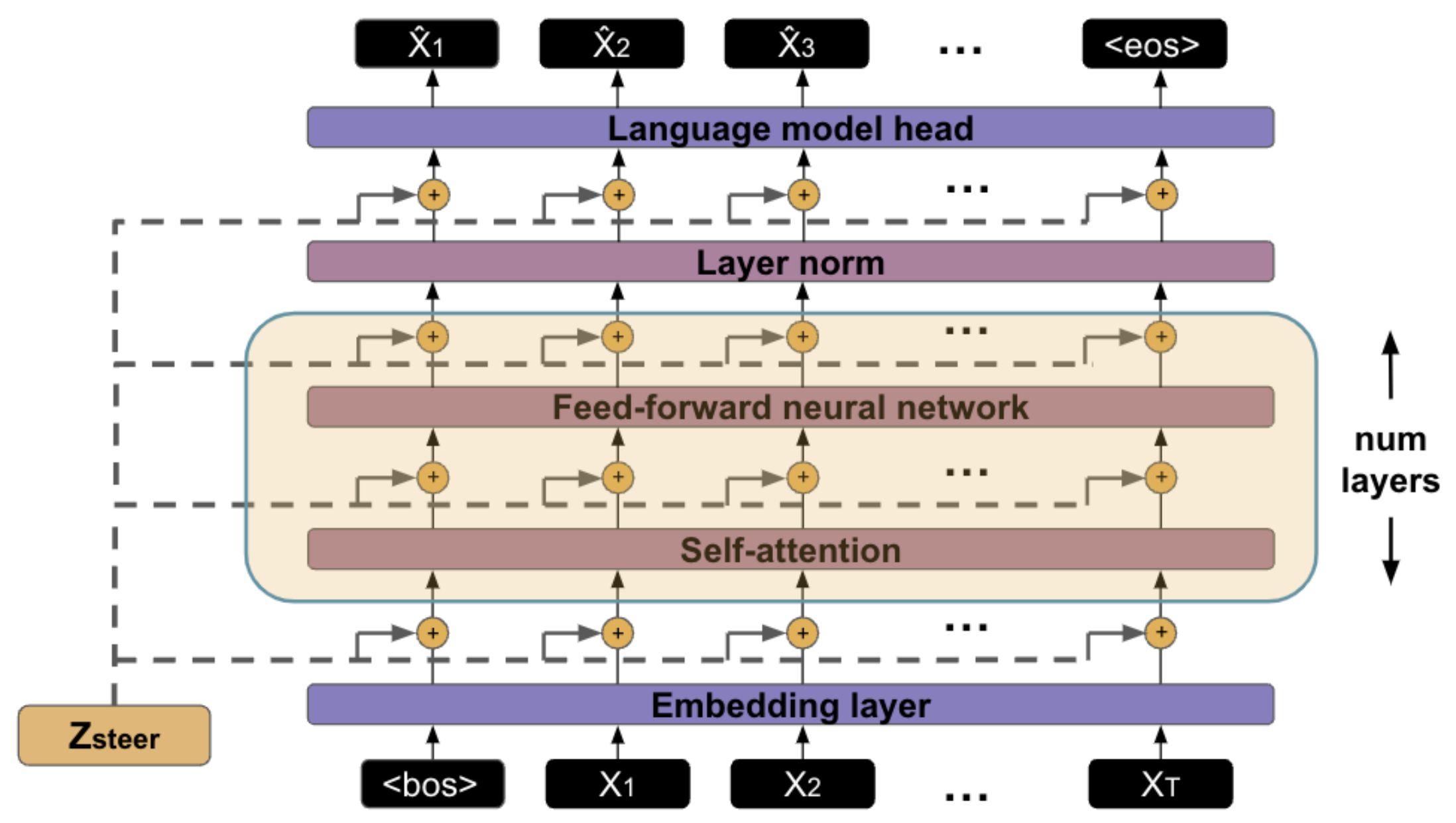 Extracting Latent Steering Vectors from Pretrained Language ModelsNishant Subramani, Nivedita Suresh, and Matthew PetersIn Findings of ACL, 2022
Extracting Latent Steering Vectors from Pretrained Language ModelsNishant Subramani, Nivedita Suresh, and Matthew PetersIn Findings of ACL, 2022 BLOOM: A 176B-Parameter Open-Access Multilingual Language ModelTeven Le Scao, Angela Fan, Christopher Akiki, Ellie Pavlick, Suzana Ili’c, Daniel Hesslow, Roman Castagn’e, Alexandra Sasha Luccioni, François Yvon, Matthias Gallé, Jonathan Tow, Alexander M. Rush, and 379 more authorsArXiv, 2022
BLOOM: A 176B-Parameter Open-Access Multilingual Language ModelTeven Le Scao, Angela Fan, Christopher Akiki, Ellie Pavlick, Suzana Ili’c, Daniel Hesslow, Roman Castagn’e, Alexandra Sasha Luccioni, François Yvon, Matthias Gallé, Jonathan Tow, Alexander M. Rush, and 379 more authorsArXiv, 2022 Can unconditional language models recover arbitrary sentences?Nishant Subramani, Samuel Bowman, and Kyunghyun ChoAdvances in NeurIPS, 2019
Can unconditional language models recover arbitrary sentences?Nishant Subramani, Samuel Bowman, and Kyunghyun ChoAdvances in NeurIPS, 2019